Learn how a North American refiner utilized Natural Language Processing project to quality check over 420K component supply records.
Challenge
A refiner was experiencing significant failures in its HF Alky units across several sites and identified incorrectly filled out intake forms in the supply chain process as a potential cause.
Solution
Pinnacle provided a data science solution that efficiently provided quality checks for over 420K supply records.
Result
The organization is now set up to improve its processes and have ongoing quality checks in the future, allowing it to better focus its expertise on follow-up inspections and increase safety and reliability across its sites.
The Challenge
A North American refiner was experiencing significant challenges with its HF Alky units across multiple sites. HF Alky units are plagued with high risk due to sensitive process material and hydrofluoric acid corrosion, resulting in significant attention from a corporate level.
Understanding the use of correct materials is critical to the safety of these units, the refiner developed a process for inspecting new construction or replacement materials brought into its plants. Upon documentation of order and delivery of new materials, plant workers were required to check a box on the intake form to indicate whether Positive Material Identification (PMI) inspection was needed. However, the organization found that the box was not being checked in all instances that it was supposed to be.
Understanding that this was more of a systemic issue affecting all its refineries and the impact spread beyond just the HF Alky units, the organization started looking for a solution to improve quality control across its sites and correct the potential impact of having incorrect material installed. The organization had approximately half a million records that needed to be reviewed to see if the “PMI Required” box was being checked. After trying to apply rudimental searching methods, the company was unable to confidently reduce the records required for review and looked to Pinnacle for help in applying data science to allow them to focus their expertise.
Pinnacle's Solution
A North American refiner was experiencing significant challenges with its HF Alky units across multiple sites. HF Alky units are plagued with high risk due to sensitive process material and hydrofluoric acid corrosion, resulting in significant attention from a corporate level.
Understanding the use of correct materials is critical to the safety of these units, the refiner developed a process for inspecting new construction or replacement materials brought into its plants. Upon documentation of order and delivery of new materials, plant workers were required to check a box on the intake form to indicate whether Positive Material Identification (PMI) inspection was needed. However, the organization found that the box was not being checked in all instances that it was supposed to be.
Understanding that this was more of a systemic issue affecting all its refineries and the impact spread beyond just the HF Alky units, the organization started looking for a solution to improve quality control across its sites and correct the potential impact of having incorrect material installed. The organization had approximately half a million records that needed to be reviewed to see if the “PMI Required” box was being checked. After trying to apply rudimental searching methods, the company was unable to confidently reduce the records required for review and looked to Pinnacle for help in applying data science to allow them to focus their expertise.
Keyword Aggregation
The first approach included 32 keywords provided by the organization that should indicate PMI concerns. Pinnacle created a tool to search through all the open text fields, and auto-searches for the keywords to indicate where “PMI required” should be checked. An additional complication in the search algorithm was the need to account for misspellings, spacing inconsistencies, punctuation, etc., in the keyword searching.
During the keyword matching process, the team was looking for two things: Do the keywords capture sufficient cases of known PMI? And do we find significant “misses” where keywords are present, but the entry is not flagged for PMI? This process required some trial and error to include close variants. For example, 316 Stainless Steel might come up as 316SS, 316 SS, 316 stainless, or other alternatives. It is important to note that a level of human error comes into play when there can be an assumption that there will be misspellings and typos on some of the documents.
Pattern Recognition via Machine Learning (ML)
The supervised ML approach is a method of example-based learning defined by use of labeled datasets. The ML algorithm looks at the text and keywords provided by the organization and tries to naturally infer which words are associated with PMI but will also learn exceptions to the rule. The computer begins to learn what kinds of keywords trigger the box to be checked and then makes recommendations. Throughout the project, the patterns learned by the computer were very consistent and offered additional keywords to be evaluated. One key benefit of this approach is that the program will continue to learn and improve as new data is introduced.
Click here to speak to our team of data science experts about how Natural Language Processing or Machine Learning can help you.
Results
Pinnacle aided in shining a light on and solving an everyday, systemic issue that can occur in any facility and how skipping a simple step can then place plant integrity in the hands of a vendor forcing assumptions that they are correct. Both data science methods provided positive results for the sample set by identifying errors for remediation. The results indicated approximately 1.8% of the organization’s records required a follow-up PMI inspection but did not have the box checked. This was significantly less than the original 5%-10% the company stakeholders had assumed at the outset of this effort.
Keyword Aggregation
With Keyword Aggregation searching for keywords, while straightforward, it is complicated first by the fact that terms related to PMI can be expressed in a variety of ways (e.g., “316 SS”, “316SS”, “316 Stainless”). Further complicating matters is that human operators often misspell terms (e.g., “Stanless Steel”) which renders brute force term matching unreliable. Pinnacle was able to leverage powerful machine learning tools such as fuzzy term matching and Bayesian spelling correction to mitigate many of these issues.
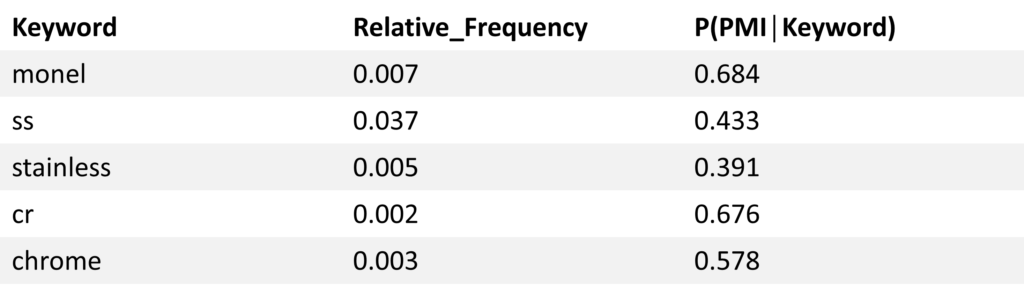
Most keywords are highly informative, meaning they occur infrequently but are highly indicative of PMI. The project found significant misses from the keywords alone, as seen in this chart. For example, “monel” should always have the box checked for PMI. Still, the study showed that the box was only checked 68% of the time, leaving 32% of the new assets uninspected. Note: the chart only represents a few of the keywords provided.
Pattern Recognition ML
Even when the difficulties of keyword matching are addressed, any set of keywords prescribed by a human Subject Matter Expert (SME) will likely be incomplete. To overcome these limitations, Pinnacle used sophisticated techniques based on supervised ML to extract keywords indicative of PMI automatically. This process ultimately enabled Pinnacle’s approach to learn new terms that indicated PMI automatically, rather than requiring a human to specify all these manually. This method also has the benefit of learning over time as new data becomes available for analysis. One aspect still being experimented with is “noisy data.” Some entries did not flag for PMI that should have been, and if not fixed, the classifiers will learn incorrect patterns that justify its findings. Pinnacle is continuing to look for methods to rectify “noisy data” which will continue to refine the keyword set. This is especially important when the keyword does not appear frequently.
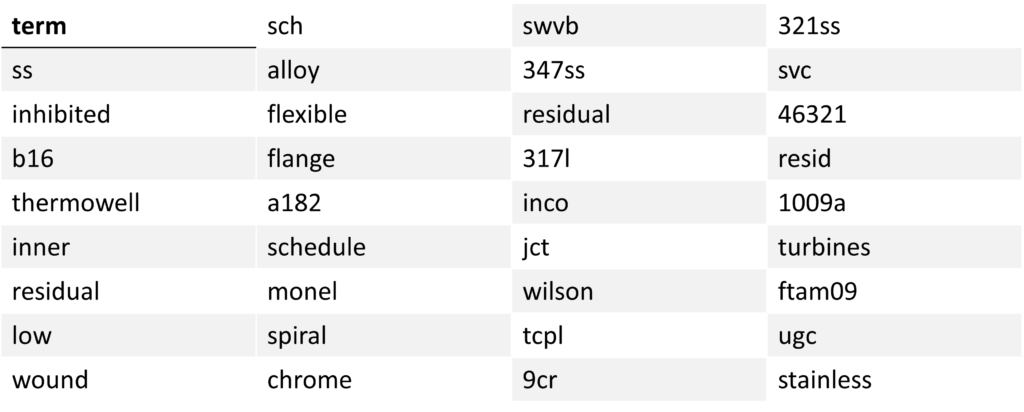
These sample results show how most of the ML recommended words make sense but occasionally find a correlation that needs to be evaluated. For example, “Wilson” kept coming up as a reoccurring term in this case. After some investigation, “Wilson” was found to be the name of an uncommon material supplier and correlated to cases where PMI was also a factor. Note: This example only represents a portion of the terms ML produced.
The ML results narrowed the list of documents to approximately 7,500 that should possibly be flagged as a “yes” but were not. This list was then reviewed by Pinnacle and site SMEs to validate the results. Post SME review, the list was again narrowed to approximately 5,000 documents.
Conclusion
Initially deemed a “catch up” exercise by stakeholders, the organization now recognizes that while processes can be improved, these tasks will need to be performed periodically for quality assurance and proper evergreening. So far, the project has reduced the number of documents that the company will have actions on by over 95%.
The final 5,000 documents left for review are spread over 17 sites, with some sites taking more of the burden than others. This information provided corporate leadership with insight into where they might need to spend additional effort in process improvement may be needed. With the conclusion of the project, the applications will continue to refine sets of keywords to be used for this exercise in the future. Now that the tools have been created, it will require minimal effort from the organization to run this exercise on new data sets.
The next step of the project will be the creation of Computerized Maintenance Management System (CMMS) load sheets to clean up the sites’ databases and categorize and prioritize the results. Pinnacle has also aided the client in creating Power BI dashboards to visualize and manage the results. This feature will help corporate leadership and the individual sites decide how to prioritize their next actions with the needed inspections.
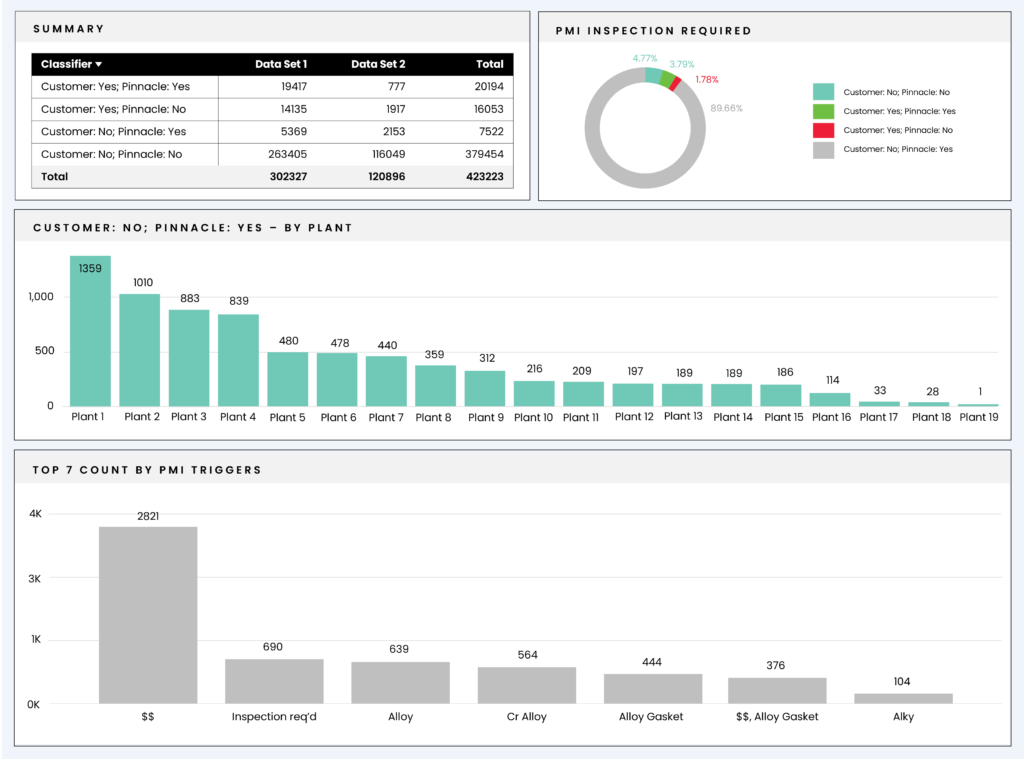
It is important to note that although this project was prompted by risks in the organization’s HF Alky units, it was an issue that plagued not just that unit but entire plants. This effort is just one example of how this technology can be used to help in an array of areas. With the completion of the whole project, the organization will continue to collaborate with Pinnacle in exploring other areas where this technology can be applied.
Stay in the know.
Providing data-driven insights, perspectives, and industrial inspiration from the forefront of the reliability transformation.